Code
library(tidyverse)
install.packages("devtools")
devtools::install_github("lbenz730/ncaahoopR")
library(ncaahoopR)This page will take you through the data sources and methodologies employed in this specific project. Furthermore, you can find brief descriptions/images/tables of the various datasets mentioned. Data must be acquired using at least one Python API and one R API. This project will use various data formats that may include labeled data, qualitative data, text data, geo data, record-data, etc.
“ncaahoopR” is an R package tailored for NCAA Basketball Play-by-Play Data analysis. It excels at retrieving play-by-play data in a tidy format. For the purposes of this project, I will start by scraping play-by-play data for the Villanova Wildcats Men’s Basketball team from both the 2019-20 and 2021-22 seasons (the 2020-21 was shortened due to COVID-19).
library(tidyverse)
install.packages("devtools")
devtools::install_github("lbenz730/ncaahoopR")
library(ncaahoopR)Once scraped, the data can be saved into a csv file for later cleaning.
Villanova1920 <- get_pbp("Villanova", "2019-20")
Villanova2122 <- get_pbp("Villanova", "2021-22")
write.csv(Villanova1920, file = "./data/raw_data/villanova1920.csv", row.names = FALSE)
write.csv(Villanova2122, file = "./data/raw_data/villanova2122.csv", row.names = FALSE)Before we move on, let’s take a look at what the raw data looks like:
head(Villanova1920)| game_id | date | home | away | play_id | half | time_remaining_half | secs_remaining | secs_remaining_absolute | description | ... | shot_y | shot_team | shot_outcome | shooter | assist | three_pt | free_throw | possession_before | possession_after | wrong_time | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| <chr> | <date> | <chr> | <chr> | <int> | <int> | <chr> | <dbl> | <dbl> | <chr> | ... | <dbl> | <chr> | <chr> | <chr> | <chr> | <lgl> | <lgl> | <chr> | <chr> | <lgl> | |
| 1 | 401169778 | 2019-11-05 | Villanova | Army | 1 | 1 | 19:37 | 2377 | 2377 | Saddiq Bey made Jumper. | ... | NA | Villanova | made | Saddiq Bey | NA | FALSE | FALSE | Villanova | Army | FALSE |
| 2 | 401169778 | 2019-11-05 | Villanova | Army | 2 | 1 | 19:16 | 2356 | 2356 | Tucker Blackwell made Jumper. Assisted by Tommy Funk. | ... | NA | Army | made | Tucker Blackwell | Tommy Funk | FALSE | FALSE | Army | Villanova | FALSE |
| 3 | 401169778 | 2019-11-05 | Villanova | Army | 3 | 1 | 19:01 | 2341 | 2341 | Foul on Jermaine Samuels. | ... | NA | NA | NA | NA | NA | NA | NA | Villanova | Army | FALSE |
| 4 | 401169778 | 2019-11-05 | Villanova | Army | 4 | 1 | 19:01 | 2341 | 2341 | Jermaine Samuels Turnover. | ... | NA | NA | NA | NA | NA | NA | NA | Villanova | Army | FALSE |
| 5 | 401169778 | 2019-11-05 | Villanova | Army | 5 | 1 | 18:42 | 2322 | 2322 | Matt Wilson made Jumper. Assisted by Tommy Funk. | ... | NA | Army | made | Matt Wilson | Tommy Funk | FALSE | FALSE | Army | Villanova | FALSE |
| 6 | 401169778 | 2019-11-05 | Villanova | Army | 6 | 1 | 18:31 | 2311 | 2311 | Jeremiah Robinson-Earl made Jumper. Assisted by Justin Moore. | ... | NA | Villanova | made | Jeremiah Robinson-Earl | Justin Moore | FALSE | FALSE | Villanova | Army | FALSE |
“Baseballr” is a package in R that focuses on baseball analytics, also known as sabremetrics. It includes various functions that can be used for scraping data from websites like FanGraphs.com, Baseball-Reference.com, and BaseballSavant.mlb.com. It also includes functions for calculating specific baseball metrics such as wOBA (weighted on-base average) and FIP (fielding independent pitching). I will mainly use this package to gather data (which uses an API as can be seen below).
The below source code was pulled from the baseballr github repository. This specific code uses a mlb api to acquire play-by-play data for a specific game. I will use these functions later on through the baseballr package.
mlb_api_call <- function(url){
res <-
httr::RETRY("GET", url)
json <- res$content %>%
rawToChar() %>%
jsonlite::fromJSON(simplifyVector = T)
return(json)
}
mlb_stats_endpoint <- function(endpoint){
all_endpoints = c(
"v1/attendance",#
"v1/conferences",#
"v1/conferences/{conferenceId}",#
"v1/awards/{awardId}/recipients",#
"v1/awards",#
"v1/baseballStats",#
"v1/eventTypes",#
"v1/fielderDetailTypes",#
"v1/gameStatus",#
"v1/gameTypes",#
"v1/highLow/types",#
"v1/hitTrajectories",#
"v1/jobTypes",#
"v1/languages",
"v1/leagueLeaderTypes",#
"v1/logicalEvents",#
"v1/metrics",#
"v1/pitchCodes",#
"v1/pitchTypes",#
"v1/playerStatusCodes",#
"v1/positions",#
"v1/reviewReasons",#
"v1/rosterTypes",#
"v1/runnerDetailTypes",#
"v1/scheduleEventTypes",#
"v1/situationCodes",#
"v1/sky",#
"v1/standingsTypes",#
"v1/statGroups",#
"v1/statTypes",#
"v1/windDirection",#
"v1/divisions",#
"v1/draft/{year}",#
"v1/draft/prospects/{year}",#
"v1/draft/{year}/latest",#
"v1.1/game/{gamePk}/feed/live",
"v1.1/game/{gamePk}/feed/live/diffPatch",#
"v1.1/game/{gamePk}/feed/live/timestamps",#
"v1/game/changes",##x
"v1/game/analytics/game",##x
"v1/game/analytics/guids",##x
"v1/game/{gamePk}/guids",##x
"v1/game/{gamePk}/{GUID}/analytics",##x
"v1/game/{gamePk}/{GUID}/contextMetricsAverages",##x
"v1/game/{gamePk}/contextMetrics",#
"v1/game/{gamePk}/winProbability",#
"v1/game/{gamePk}/boxscore",#
"v1/game/{gamePk}/content",#
"v1/game/{gamePk}/feed/color",##x
"v1/game/{gamePk}/feed/color/diffPatch",##x
"v1/game/{gamePk}/feed/color/timestamps",##x
"v1/game/{gamePk}/linescore",#
"v1/game/{gamePk}/playByPlay",#
"v1/gamePace",#
"v1/highLow/{orgType}",#
"v1/homeRunDerby/{gamePk}",#
"v1/homeRunDerby/{gamePk}/bracket",#
"v1/homeRunDerby/{gamePk}/pool",#
"v1/league",#
"v1/league/{leagueId}/allStarBallot",#
"v1/league/{leagueId}/allStarWriteIns",#
"v1/league/{leagueId}/allStarFinalVote",#
"v1/people",#
"v1/people/freeAgents",#
"v1/people/{personId}",##U
"v1/people/{personId}/stats/game/{gamePk}",#
"v1/people/{personId}/stats/game/current",#
"v1/jobs",#
"v1/jobs/umpires",#
"v1/jobs/datacasters",#
"v1/jobs/officialScorers",#
"v1/jobs/umpires/games/{umpireId}",##x
"v1/schedule/",#
"v1/schedule/games/tied",#
"v1/schedule/postseason",#
"v1/schedule/postseason/series",#
"v1/schedule/postseason/tuneIn",##x
"v1/seasons",#
"v1/seasons/all",#
"v1/seasons/{seasonId}",#
"v1/sports",#
"v1/sports/{sportId}",#
"v1/sports/{sportId}/players",#
"v1/standings",#
"v1/stats",#
"v1/stats/metrics",##x
"v1/stats/leaders",#
"v1/stats/streaks",##404
"v1/teams",#
"v1/teams/history",#
"v1/teams/stats",#
"v1/teams/stats/leaders",#
"v1/teams/affiliates",#
"v1/teams/{teamId}",#
"v1/teams/{teamId}/stats",#
"v1/teams/{teamId}/affiliates",#
"v1/teams/{teamId}/alumni",#
"v1/teams/{teamId}/coaches",#
"v1/teams/{teamId}/personnel",#
"v1/teams/{teamId}/leaders",#
"v1/teams/{teamId}/roster",##x
"v1/teams/{teamId}/roster/{rosterType}",#
"v1/venues"#
)
base_url = glue::glue('http://statsapi.mlb.com/api/{endpoint}')
return(base_url)
}
Below is an example usage of the api call using a random game id.
x <- "http://statsapi.mlb.com/api/v1/game/575156/playByPlay"
output <- mlb_api_call(x)“output” is a very messy list that is extremely long. Instead of printing “output”, below are three images of part of the list.
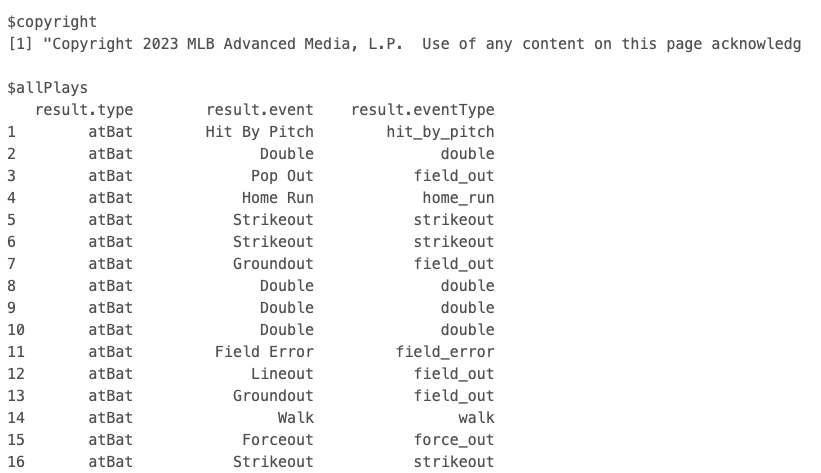

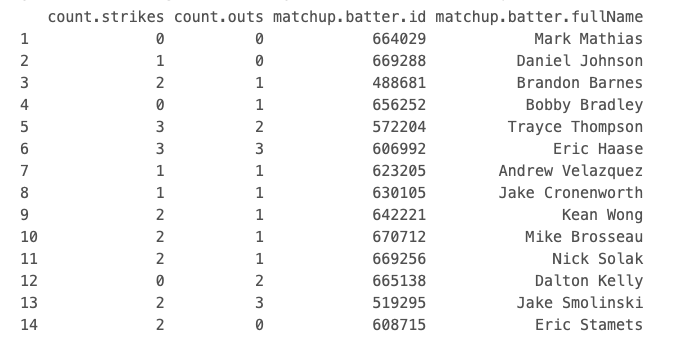
The below code builds on the previous code, returning a tibble that includes over 100 columns of data provided by the MLB Stats API at a pitch level. As you will see, the output is much cleaner and easier to work with.
#' @rdname mlb_pbp
#' @title **Acquire pitch-by-pitch data for Major and Minor League games**
#'
#' @param game_pk The date for which you want to find game_pk values for MLB games
#' @importFrom jsonlite fromJSON
#' @return Returns a tibble that includes over 100 columns of data provided
#' by the MLB Stats API at a pitch level.
#'
#' Some data will vary depending on the
#' park and the league level, as most sensor data is not available in
#' minor league parks via this API. Note that the column names have mostly
#' been left as-is and there are likely duplicate columns in terms of the
#' information they provide. I plan to clean the output up down the road, but
#' for now I am leaving the majority as-is.
#'
#' Both major and minor league pitch-by-pitch data can be pulled with this function.
#'
#' |col_name |types |
#' |:------------------------------|:---------|
#' |game_pk |numeric |
#' |game_date |character |
#' |index |integer |
#' |startTime |character |
#' |endTime |character |
#' |isPitch |logical |
#' |type |character |
#' |playId |character |
#' |pitchNumber |integer |
#' |details.description |character |
#' |details.event |character |
#' |details.awayScore |integer |
#' |details.homeScore |integer |
#' |details.isScoringPlay |logical |
#' |details.hasReview |logical |
#' |details.code |character |
#' |details.ballColor |character |
#' |details.isInPlay |logical |
#' |details.isStrike |logical |
#' |details.isBall |logical |
#' |details.call.code |character |
#' |details.call.description |character |
#' |count.balls.start |integer |
#' |count.strikes.start |integer |
#' |count.outs.start |integer |
#' |player.id |integer |
#' |player.link |character |
#' |pitchData.strikeZoneTop |numeric |
#' |pitchData.strikeZoneBottom |numeric |
#' |details.fromCatcher |logical |
#' |pitchData.coordinates.x |numeric |
#' |pitchData.coordinates.y |numeric |
#' |hitData.trajectory |character |
#' |hitData.hardness |character |
#' |hitData.location |character |
#' |hitData.coordinates.coordX |numeric |
#' |hitData.coordinates.coordY |numeric |
#' |actionPlayId |character |
#' |details.eventType |character |
#' |details.runnerGoing |logical |
#' |position.code |character |
#' |position.name |character |
#' |position.type |character |
#' |position.abbreviation |character |
#' |battingOrder |character |
#' |atBatIndex |character |
#' |result.type |character |
#' |result.event |character |
#' |result.eventType |character |
#' |result.description |character |
#' |result.rbi |integer |
#' |result.awayScore |integer |
#' |result.homeScore |integer |
#' |about.atBatIndex |integer |
#' |about.halfInning |character |
#' |about.inning |integer |
#' |about.startTime |character |
#' |about.endTime |character |
#' |about.isComplete |logical |
#' |about.isScoringPlay |logical |
#' |about.hasReview |logical |
#' |about.hasOut |logical |
#' |about.captivatingIndex |integer |
#' |count.balls.end |integer |
#' |count.strikes.end |integer |
#' |count.outs.end |integer |
#' |matchup.batter.id |integer |
#' |matchup.batter.fullName |character |
#' |matchup.batter.link |character |
#' |matchup.batSide.code |character |
#' |matchup.batSide.description |character |
#' |matchup.pitcher.id |integer |
#' |matchup.pitcher.fullName |character |
#' |matchup.pitcher.link |character |
#' |matchup.pitchHand.code |character |
#' |matchup.pitchHand.description |character |
#' |matchup.splits.batter |character |
#' |matchup.splits.pitcher |character |
#' |matchup.splits.menOnBase |character |
#' |batted.ball.result |factor |
#' |home_team |character |
#' |home_level_id |integer |
#' |home_level_name |character |
#' |home_parentOrg_id |integer |
#' |home_parentOrg_name |character |
#' |home_league_id |integer |
#' |home_league_name |character |
#' |away_team |character |
#' |away_level_id |integer |
#' |away_level_name |character |
#' |away_parentOrg_id |integer |
#' |away_parentOrg_name |character |
#' |away_league_id |integer |
#' |away_league_name |character |
#' |batting_team |character |
#' |fielding_team |character |
#' |last.pitch.of.ab |character |
#' |pfxId |character |
#' |details.trailColor |character |
#' |details.type.code |character |
#' |details.type.description |character |
#' |pitchData.startSpeed |numeric |
#' |pitchData.endSpeed |numeric |
#' |pitchData.zone |integer |
#' |pitchData.typeConfidence |numeric |
#' |pitchData.plateTime |numeric |
#' |pitchData.extension |numeric |
#' |pitchData.coordinates.aY |numeric |
#' |pitchData.coordinates.aZ |numeric |
#' |pitchData.coordinates.pfxX |numeric |
#' |pitchData.coordinates.pfxZ |numeric |
#' |pitchData.coordinates.pX |numeric |
#' |pitchData.coordinates.pZ |numeric |
#' |pitchData.coordinates.vX0 |numeric |
#' |pitchData.coordinates.vY0 |numeric |
#' |pitchData.coordinates.vZ0 |numeric |
#' |pitchData.coordinates.x0 |numeric |
#' |pitchData.coordinates.y0 |numeric |
#' |pitchData.coordinates.z0 |numeric |
#' |pitchData.coordinates.aX |numeric |
#' |pitchData.breaks.breakAngle |numeric |
#' |pitchData.breaks.breakLength |numeric |
#' |pitchData.breaks.breakY |numeric |
#' |pitchData.breaks.spinRate |integer |
#' |pitchData.breaks.spinDirection |integer |
#' |hitData.launchSpeed |numeric |
#' |hitData.launchAngle |numeric |
#' |hitData.totalDistance |numeric |
#' |injuryType |character |
#' |umpire.id |integer |
#' |umpire.link |character |
#' |isBaseRunningPlay |logical |
#' |isSubstitution |logical |
#' |about.isTopInning |logical |
#' |matchup.postOnFirst.id |integer |
#' |matchup.postOnFirst.fullName |character |
#' |matchup.postOnFirst.link |character |
#' |matchup.postOnSecond.id |integer |
#' |matchup.postOnSecond.fullName |character |
#' |matchup.postOnSecond.link |character |
#' |matchup.postOnThird.id |integer |
#' |matchup.postOnThird.fullName |character |
#' |matchup.postOnThird.link |character |
#' @export
#' @examples \donttest{
#' try(mlb_pbp(game_pk = 632970))
#' }
mlb_pbp <- function(game_pk) {
mlb_endpoint <- mlb_stats_endpoint(glue::glue("v1.1/game/{game_pk}/feed/live"))
tryCatch(
expr = {
payload <- mlb_endpoint %>%
mlb_api_call() %>%
jsonlite::toJSON() %>%
jsonlite::fromJSON(flatten = TRUE)
plays <- payload$liveData$plays$allPlays$playEvents %>%
dplyr::bind_rows()
at_bats <- payload$liveData$plays$allPlays
current <- payload$liveData$plays$currentPlay
game_status <- payload$gameData$status$abstractGameState
home_team <- payload$gameData$teams$home$name
home_level <- payload$gameData$teams$home$sport
home_league <- payload$gameData$teams$home$league
away_team <- payload$gameData$teams$away$name
away_level <- payload$gameData$teams$away$sport
away_league <- payload$gameData$teams$away$league
columns <- lapply(at_bats, function(x) class(x)) %>%
dplyr::bind_rows(.id = "variable")
cols <- c(colnames(columns))
classes <- c(t(unname(columns[1,])))
df <- data.frame(cols, classes)
list_columns <- df %>%
dplyr::filter(.data$classes == "list") %>%
dplyr::pull("cols")
at_bats <- at_bats %>%
dplyr::select(-c(tidyr::one_of(list_columns)))
pbp <- plays %>%
dplyr::left_join(at_bats, by = c("endTime" = "playEndTime"))
pbp <- pbp %>%
tidyr::fill("atBatIndex":"matchup.splits.menOnBase", .direction = "up") %>%
dplyr::mutate(
game_pk = game_pk,
game_date = substr(payload$gameData$datetime$dateTime, 1, 10)) %>%
dplyr::select("game_pk", "game_date", tidyr::everything())
pbp <- pbp %>%
dplyr::mutate(
matchup.batter.fullName = factor(.data$matchup.batter.fullName),
matchup.pitcher.fullName = factor(.data$matchup.pitcher.fullName),
atBatIndex = factor(.data$atBatIndex)
# batted.ball.result = case_when(!result.event %in% c(
# "Single", "Double", "Triple", "Home Run") ~ "Out/Other",
# TRUE ~ result.event),
# batted.ball.result = factor(batted.ball.result,
# levels = c("Single", "Double", "Triple", "Home Run", "Out/Other"))
) %>%
dplyr::mutate(
home_team = home_team,
home_level_id = home_level$id,
home_level_name = home_level$name,
home_parentOrg_id = payload$gameData$teams$home$parentOrgId,
home_parentOrg_name = payload$gameData$teams$home$parentOrgName,
home_league_id = home_league$id,
home_league_name = home_league$name,
away_team = away_team,
away_level_id = away_level$id,
away_level_name = away_level$name,
away_parentOrg_id = payload$gameData$teams$away$parentOrgId,
away_parentOrg_name = payload$gameData$teams$away$parentOrgName,
away_league_id = away_league$id,
away_league_name = away_league$name,
batting_team = factor(ifelse(.data$about.halfInning == "bottom",
.data$home_team,
.data$away_team)),
fielding_team = factor(ifelse(.data$about.halfInning == "bottom",
.data$away_team,
.data$home_team)))
pbp <- pbp %>%
dplyr::arrange(desc(.data$atBatIndex), desc(.data$pitchNumber))
pbp <- pbp %>%
dplyr::group_by(.data$atBatIndex) %>%
dplyr::mutate(
last.pitch.of.ab = ifelse(.data$pitchNumber == max(.data$pitchNumber), "true", "false"),
last.pitch.of.ab = factor(.data$last.pitch.of.ab)) %>%
dplyr::ungroup()
pbp <- dplyr::bind_rows(baseballr::stats_api_live_empty_df, pbp)
check_home_level <- pbp %>%
dplyr::distinct(.data$home_level_id) %>%
dplyr::pull()
# this will need to be updated in the future to properly estimate X,Z coordinates at the minor league level
# if(check_home_level != 1) {
#
# pbp <- pbp %>%
# dplyr::mutate(pitchData.coordinates.x = -pitchData.coordinates.x,
# pitchData.coordinates.y = -pitchData.coordinates.y)
#
# pbp <- pbp %>%
# dplyr::mutate(pitchData.coordinates.pX_est = predict(x_model, pbp),
# pitchData.coordinates.pZ_est = predict(y_model, pbp))
#
# pbp <- pbp %>%
# dplyr::mutate(pitchData.coordinates.x = -pitchData.coordinates.x,
# pitchData.coordinates.y = -pitchData.coordinates.y)
# }
pbp <- pbp %>%
dplyr::rename(
"count.balls.start" = "count.balls.x",
"count.strikes.start" = "count.strikes.x",
"count.outs.start" = "count.outs.x",
"count.balls.end" = "count.balls.y",
"count.strikes.end" = "count.strikes.y",
"count.outs.end" = "count.outs.y") %>%
make_baseballr_data("MLB Play-by-Play data from MLB.com",Sys.time())
},
error = function(e) {
message(glue::glue("{Sys.time()}: Invalid arguments provided"))
},
finally = {
}
)
return(pbp)
}
#' @rdname get_pbp_mlb
#' @title **(legacy) Acquire pitch-by-pitch data for Major and Minor League games**
#' @inheritParams mlb_pbp
#' @return Returns a tibble that includes over 100 columns of data provided
#' by the MLB Stats API at a pitch level.
#' @keywords legacy
#' @export
# get_pbp_mlb <- mlb_pbpHere is an example using the mlb_pbp function.
example <- (mlb_pbp(575156))
head(example)2023-10-12 13:40:46.684707: Invalid arguments provided
| game_pk | game_date | index | startTime | endTime | isPitch | type | playId | pitchNumber | details.description | ... | about.isTopInning | matchup.postOnFirst.id | matchup.postOnFirst.fullName | matchup.postOnFirst.link | matchup.postOnSecond.id | matchup.postOnSecond.fullName | matchup.postOnSecond.link | matchup.postOnThird.id | matchup.postOnThird.fullName | matchup.postOnThird.link |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| <dbl> | <chr> | <int> | <chr> | <chr> | <lgl> | <chr> | <chr> | <int> | <chr> | ... | <lgl> | <int> | <chr> | <chr> | <int> | <chr> | <chr> | <int> | <chr> | <chr> |
| 575156 | 2019-06-01 | 5 | 2019-06-01T15:38:42.000Z | 2019-06-01T19:38:07.354Z | TRUE | pitch | 05751566-0846-0063-000c-f08cd117d70a | 6 | In play, out(s) | ... | TRUE | NA | NA | NA | NA | NA | NA | NA | NA | NA |
| 575156 | 2019-06-01 | 4 | 2019-06-01T15:38:19.000Z | 2019-06-01T15:38:42.000Z | TRUE | pitch | 05751566-0846-0053-000c-f08cd117d70a | 5 | Foul | ... | TRUE | NA | NA | NA | NA | NA | NA | NA | NA | NA |
| 575156 | 2019-06-01 | 3 | 2019-06-01T15:38:02.000Z | 2019-06-01T15:38:19.000Z | TRUE | pitch | 05751566-0846-0043-000c-f08cd117d70a | 4 | Swinging Strike | ... | TRUE | NA | NA | NA | NA | NA | NA | NA | NA | NA |
| 575156 | 2019-06-01 | 2 | 2019-06-01T15:37:45.000Z | 2019-06-01T15:38:02.000Z | TRUE | pitch | 05751566-0846-0033-000c-f08cd117d70a | 3 | Swinging Strike | ... | TRUE | NA | NA | NA | NA | NA | NA | NA | NA | NA |
| 575156 | 2019-06-01 | 1 | 2019-06-01T15:37:31.000Z | 2019-06-01T15:37:45.000Z | TRUE | pitch | 05751566-0846-0023-000c-f08cd117d70a | 2 | Ball | ... | TRUE | NA | NA | NA | NA | NA | NA | NA | NA | NA |
| 575156 | 2019-06-01 | 0 | 2019-06-01T15:37:15.000Z | 2019-06-01T15:37:31.000Z | TRUE | pitch | 05751566-0846-0013-000c-f08cd117d70a | 1 | Ball | ... | TRUE | NA | NA | NA | NA | NA | NA | NA | NA | NA |
I might use more data eventually, but for now I am scraping two series of games from the 2023 season.
library(baseballr)The below code allows me to find the correct game_pk values that I can then use to pull play-by-play data. The output is hidden from this code chunk because it is very long and not necessary for understanding.
#mlb_game_pks("2023-06-25")
# mlb_game_pks("2023-06-24")
# mlb_game_pks("2023-06-23")The two series of games that I am scraping are Diamondbacks/Giants and Mariners/Orioles. The game_pk values, which were acquired using the above code, are as follows: 717641, 717639, 717612, 717651, 717628, 717627. In the following chunk I will use the mlb_pbp function to pull play-by-play data for these games and save it to a csv file. You can see what this data looks like below:
x <- c(717641, 717639, 717612, 717651, 717628, 717627)
result <- lapply(x, mlb_pbp)
combined_tibble <- bind_rows(result)
# Save the data to a CSV file
write.csv(combined_tibble, file = "./data/raw_data/baseballr_six_games.csv", row.names = FALSE)
head(combined_tibble)| game_pk | game_date | index | startTime | endTime | isPitch | type | playId | pitchNumber | details.description | ... | matchup.postOnThird.link | reviewDetails.isOverturned | reviewDetails.inProgress | reviewDetails.reviewType | reviewDetails.challengeTeamId | base | details.violation.type | details.violation.description | details.violation.player.id | details.violation.player.fullName |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| <dbl> | <chr> | <int> | <chr> | <chr> | <lgl> | <chr> | <chr> | <int> | <chr> | ... | <chr> | <lgl> | <lgl> | <chr> | <int> | <int> | <chr> | <chr> | <int> | <chr> |
| 717641 | 2023-06-24 | 2 | 2023-06-24T04:40:41.468Z | 2023-06-24T04:40:49.543Z | TRUE | pitch | a8483d6b-3cff-4190-827c-1b4c71f60ef8 | 3 | In play, out(s) | ... | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA |
| 717641 | 2023-06-24 | 1 | 2023-06-24T04:40:24.685Z | 2023-06-24T04:40:28.580Z | TRUE | pitch | 49eba946-3aaa-4260-895b-3de29cb49043 | 2 | Foul | ... | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA |
| 717641 | 2023-06-24 | 0 | 2023-06-24T04:40:08.036Z | 2023-06-24T04:40:12.278Z | TRUE | pitch | f879f5a0-8570-4594-ae73-3f09d1a53ee1 | 1 | Ball | ... | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA |
| 717641 | 2023-06-24 | 6 | 2023-06-24T04:39:08.422Z | 2023-06-24T04:39:16.691Z | TRUE | pitch | 3077f596-0221-4469-9841-f1684c629288 | 6 | In play, out(s) | ... | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA |
| 717641 | 2023-06-24 | 5 | 2023-06-24T04:38:49.567Z | 2023-06-24T04:38:53.482Z | TRUE | pitch | 21a33e9d-e596-408b-9168-141acc0b1b63 | 5 | Foul | ... | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA |
| 717641 | 2023-06-24 | 4 | 2023-06-24T04:38:32.110Z | 2023-06-24T04:38:36.156Z | TRUE | pitch | db083639-52be-41f4-b6d9-f72601ef1508 | 4 | Foul | ... | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA |
In Python, we can leverage the News API to retrieve textual data related to our topic, aiming to glean insights into public perspectives on streaks in sports.
API_KEY='05d7ae99b5b7455191c97c2c5c3a1f9b'
import requests
import json
import re
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizerAfter loading in relevant libraries and setting up the API, we can use the following code to retrieve the top 100 headlines related to our topic.
#updated code
baseURL = "https://newsapi.org/v2/everything?"
total_requests=2
verbose=True
def gettingdata(TOPIC):
URLpost = {'apiKey': API_KEY,
'q': '+'+TOPIC,
'sortBy': 'relevancy',
'totalRequests': 1}
print(baseURL)
print(URLpost)
#GET DATA FROM API
response = requests.get(baseURL, URLpost) #request data from the server
print(response.url);
response = response.json() #extract txt data from request into json
# PRETTY PRINT
# https://www.digitalocean.com/community/tutorials/python-pretty-print-json
#print(json.dumps(response, indent=2))
# #GET TIMESTAMP FOR PULL REQUEST
from datetime import datetime
timestamp = datetime.now().strftime("%Y-%m-%d-H%H-M%M-S%S")
# SAVE TO FILE
with open(timestamp+'-newapi-raw-data.json', 'w') as outfile:
json.dump(response, outfile, indent=4)
def string_cleaner(input_string):
try:
out=re.sub(r"""
[,.;@#?!&$-]+ # Accept one or more copies of punctuation
\ * # plus zero or more copies of a space,
""",
" ", # and replace it with a single space
input_string, flags=re.VERBOSE)
#REPLACE SELECT CHARACTERS WITH NOTHING
out = re.sub('[’.]+', '', input_string)
#ELIMINATE DUPLICATE WHITESPACES USING WILDCARDS
out = re.sub(r'\s+', ' ', out)
#CONVERT TO LOWER CASE
out=out.lower()
except:
print("ERROR")
out=''
return out
article_list=response['articles'] #list of dictionaries for each article
article_keys=article_list[0].keys()
#print("AVAILABLE KEYS:")
#print(article_keys)
index=0
cleaned_data=[];
for article in article_list:
tmp=[]
if(verbose):
print("#------------------------------------------")
print("#",index)
print("#------------------------------------------")
for key in article_keys:
if(verbose):
print("----------------")
print(key)
print(article[key])
print("----------------")
#if(key=='source'):
#src=string_cleaner(article[key]['name'])
#tmp.append(src)
#if(key=='author'):
#author=string_cleaner(article[key])
#ERROR CHECK (SOMETIMES AUTHOR IS SAME AS PUBLICATION)
#if(src in author):
#print(" AUTHOR ERROR:",author);author='NA'
#tmp.append(author)
if(key=='title'):
tmp.append(string_cleaner(article[key]))
if(key=='description'):
tmp.append(string_cleaner(article[key]))
# if(key=='content'):
# tmp.append(string_cleaner(article[key]))
#if(key=='publishedAt'):
#DEFINE DATA PATERN FOR RE TO CHECK .* --> wildcard
#ref = re.compile('.*-.*-.*T.*:.*:.*Z')
#date=article[key]
#if(not ref.match(date)):
#print(" DATE ERROR:",date); date="NA"
#tmp.append(date)
cleaned_data.append(tmp)
index+=1
text = cleaned_data
return textNow we can use the above functiont to gather textual data related to the topic.
# Obtain data using gettingdata function
TOPIC = 'sports streak'
hotstreak = gettingdata(TOPIC)Finally, let’s use the NLTK library in Python to analyze the sentiment of textual data (titles and descriptions) from the hotstreak dataset. The following code calculates sentiment scores using the VADER sentiment analysis tool and then saves the results, including titles, descriptions, and sentiment scores, into a JSON file named ‘sentiment_scores.json’. This will be useful for later analysis.
import nltk
from nltk.sentiment import SentimentIntensityAnalyzer
nltk.download('vader_lexicon')
sia = SentimentIntensityAnalyzer()
sentiment_scores = []
for text_pair in hotstreak:
title, description = text_pair
score = sia.polarity_scores(description)
sentiment_scores.append({'title': title, 'description': description, 'sentiment_score': score})
with open('sentiment_scores.json', 'w') as json_file:
json.dump(sentiment_scores, json_file, indent=4)[nltk_data] Downloading package vader_lexicon to
[nltk_data] /Users/williammcgloin/nltk_data...
[nltk_data] Package vader_lexicon is already up-to-date!Below you can see the first few rows of the newsapi.csv file:

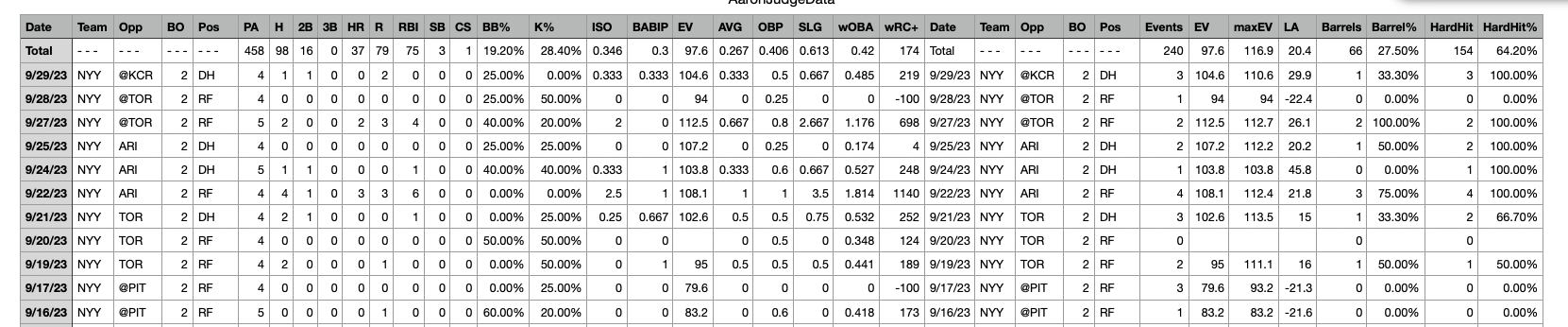
I also want to scrape specific data from fangraphs. I downloaded a few tables that had game data for Aaron Judge and then merged them together. Later research might scrape more player data. Below are screen shots of the initial csv file.

How much data can be stored in a glacier? A frostbite!
