On this page, our attention turns to the implementation of Decision Trees and Random Forest using the same NCAA shot data from the 2021-22 Villanova season that was utilized in the clustering and dimensionality reduction tabs. We’ll start by loading relevant libraries and reading in the data.
Code
# import relevant librariesimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as sns# read in the datadf = pd.read_csv('./data/modified_data/nova_final.csv')df.info()
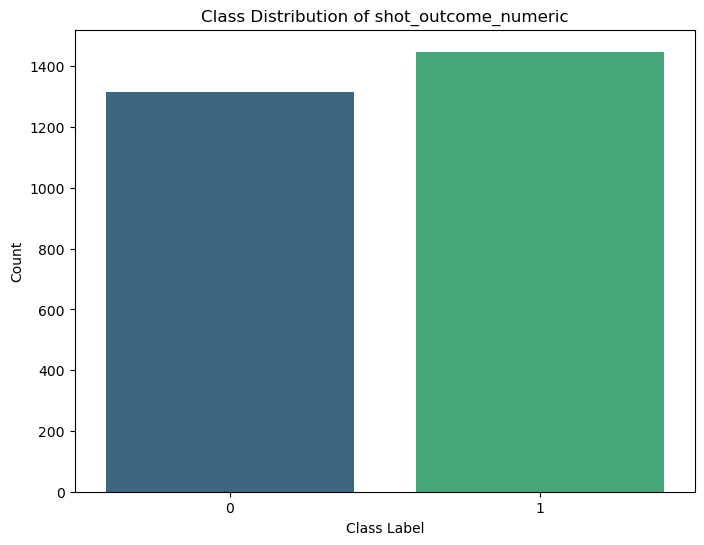
Let’s start by examining the distribution of class labels, specifically distinguishing between made and missed shots:
Code
# Compute the distribution of class labelsclass_distribution = df['shot_outcome_numeric'].value_counts()# Print the distributionprint("Class Distribution:")print(class_distribution)
Class Distribution:
1 1448
0 1316
Name: shot_outcome_numeric, dtype: int64
Code
# Plot the class distributionplt.figure(figsize=(8, 6))sns.countplot(x='shot_outcome_numeric', data=df, palette='viridis')plt.title('Class Distribution of shot_outcome_numeric')plt.xlabel('Class Label')plt.ylabel('Count')plt.show()
There is a slight imbalance in class distribution for the shot_outcome_numeric target variable (class label). There are 1448 instances of ‘made shot’ (Class Label ‘1’) and 1316 instances of ‘missed shot’ (Class Label ‘0’). This class imbalance can influence the performance of the classification model. It’s essential to consider metrics beyond accuracy, such as precision and recall of the data, to gain a comprehensive understanding. Additionally, it’s worth noting that a model predicting ‘1’ for every instance would achieve 52.4% accuracy, so any model with an accuracy below this threshold does not provide meaningful predictions. Below is code that runs a random classifier on the data to see if it can beat the 52.4% accuracy threshold.
Code
from collections import Counterfrom sklearn.metrics import accuracy_score, precision_recall_fscore_support# Random Classifier functiondef random_classifier(y_data): ypred = np.random.randint(2, size=len(y_data)) # Random predictions (0 or 1)print("-----RANDOM CLASSIFIER-----")print("Count of Predictions:", Counter(ypred).values())print("Probability of Predictions:", np.fromiter(Counter(ypred).values(), dtype=float) /len(y_data)) accuracy = accuracy_score(y_data, ypred) precision, recall, fscore, _ = precision_recall_fscore_support(y_data, ypred)print("Accuracy:", accuracy)print("Precision (Class 0, Class 1):", precision)print("Recall (Class 0, Class 1):", recall)print("F1-score (Class 0, Class 1):", fscore)# Using the 'shot_outcome_numeric' column as labelsy = df['shot_outcome_numeric']# Running the random classifierrandom_classifier(y)
-----RANDOM CLASSIFIER-----
Count of Predictions: dict_values([1357, 1407])
Probability of Predictions: [0.49095514 0.50904486]
Accuracy: 0.5032561505065123
Precision (Class 0, Class 1): [0.47974414 0.52763449]
Recall (Class 0, Class 1): [0.51291793 0.49447514]
F1-score (Class 0, Class 1): [0.49577672 0.51051693]
The random classifier acts as a rudimentary model that makes predictions through random guessing. Its primary role is to provide a fundamental benchmark for assessing the efficacy of more sophisticated models. Specifically applied to predicting basketball shot outcomes, this classifier yields an accuracy of approximately 50%, falling short of consistently predicting ‘1’ (as established earlier). When evaluating advanced models, the goal is for them to surpass this random guessing baseline (and the 52.4% baseline from always guessing the most common class), demonstrating their ability to discern meaningful patterns within the data.
Decision Tree
Theory
Decision Trees are powerful machine learning algorithms used for classification and regression tasks, providing a hierarchical structure whereby nodes represent decisions based on specific features. The dataset is recursively split at decision nodes using criteria like Gini impurity for classification. Each leaf node corresponds to a class label in classification or a numerical value in regression, making the final predictions.
The simplicity and interpretability of Decision Trees make them widely applicable, but their susceptibility to overfitting necessitates techniques like pruning. Pruning involves removing non-contributive parts of the tree. Decision Trees offer insights into feature importance, with features near the top of the tree contributing more to predictive power.
Applying Decision Trees to real-world scenarios involves defining rules for classification based on the dataset’s features. These rules provide a transparent decision-making process, making Decision Trees particularly useful for explaining predictions to non-experts. In the context of the basketball data I have been using, Decision Trees could form rules like “if the shot value is less than 2, classify it as a made shot.” Feature selection and hyperparameter tuning further refine these trees to better fit the data, exemplifying their adaptability to various applications. The Gini Index is a common measure used in Decision Trees to determine optimal splits, minimizing impurity and enhancing predictive accuracy. Despite their advantages, Decision Trees’ potential overfitting is mitigated by minimizing the number of layers or employing advanced techniques.
Implementation
In the following code, we begin by importing the necessary libraries. Subsequently, we partition the data into subsets, distinguishing features and the target variable. Further, we perform another split on the data into training and test sets, allowing us to train a Decision Tree model on the training data and assess its performance using the test data. We then print the accuracy value of this model on the test data.
Code
# laod in relevant librariesimport pandas as pdfrom sklearn.tree import DecisionTreeClassifier from sklearn.model_selection import train_test_split from sklearn import metrics # split data in features and target variablefeature_columns = ['shot_value', 'field_goal_percentage', 'lag1', 'home_crowd', 'score_diff', 'game_num']X = df[feature_columns].copy()target_column = ['shot_outcome_numeric']Y = df[target_column].copy()# Split data into training and test setX_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=1) # 70% training and 30% test# Create Decision Tree classifer objectmodel = DecisionTreeClassifier()# Train Decision Tree Classifermoodel = model.fit(X_train,Y_train)#Predict the response for test datasetY_pred = model.predict(X_test)# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(Y_test, Y_pred))
Accuracy: 0.5590361445783133
This decision tree did better than both baseline comparisons (both the random classifier and always guessing the most common class label). However, it is still not a great model; the accuracy only slightly improved to 56%. Let’s visualize the model below.
The initial decision tree above seems excessively large, indicating potential overfitting to the data. To address this, we’ll adjust the hyperparameters below.
Hyper-Parameter Tuning
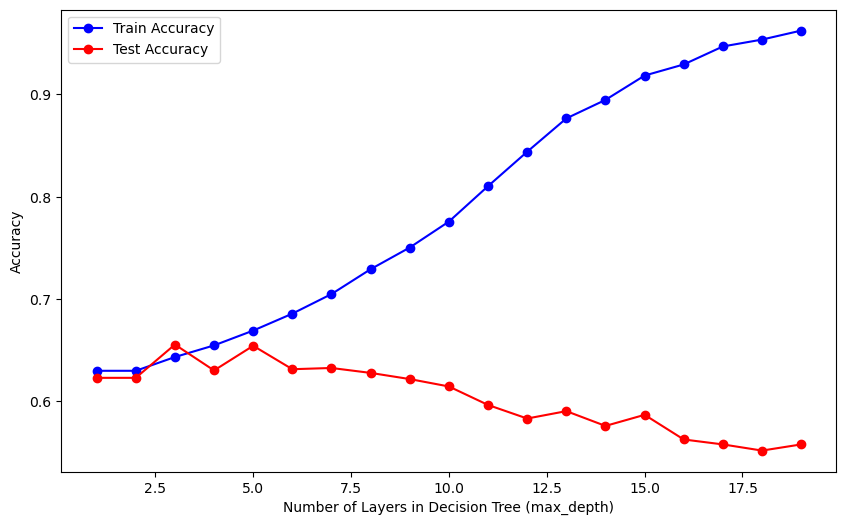
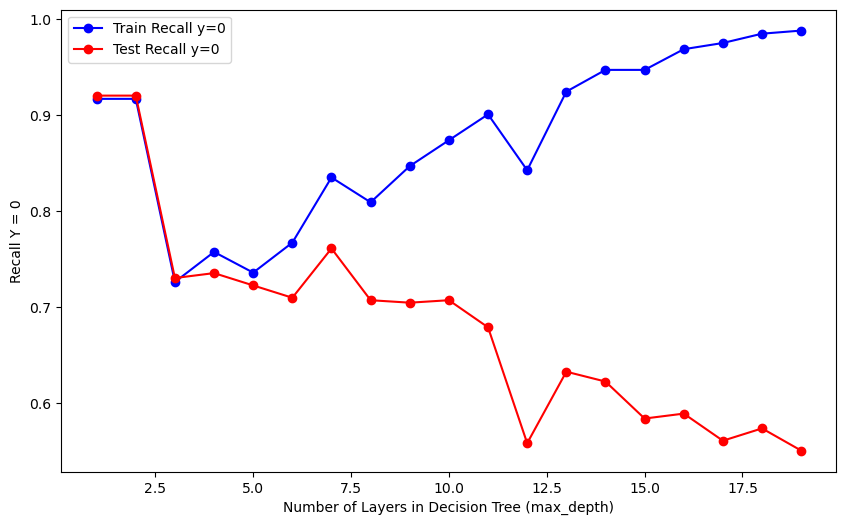
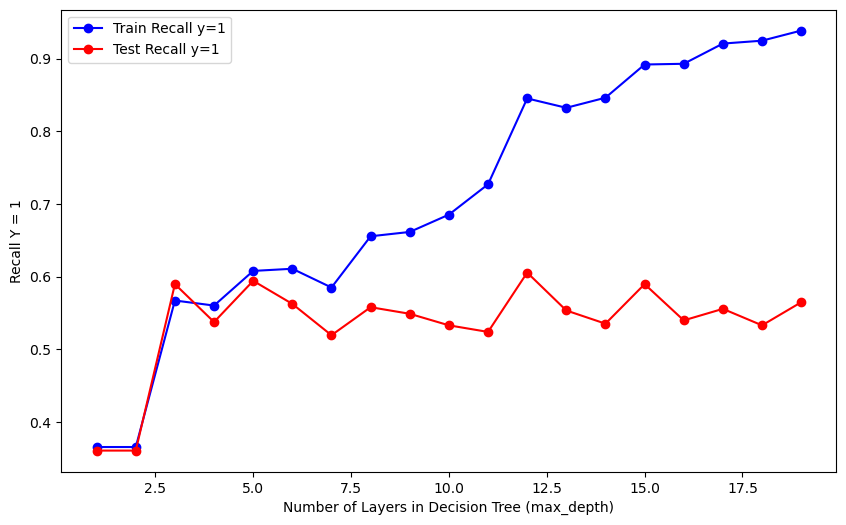
The provided code iterates through different values for the hyperparameter (number of layers) and generates three plots to visualize the model’s performance. The plots show the accuracy and recall for both training and test datasets, with varying numbers of layers in the Decision Tree (controlled by the max_depth hyperparameter). The blue lines represent training results, while the red lines depict test results.
Code
from sklearn.metrics import accuracy_score, recall_scoretest_results=[]train_results=[]for num_layer inrange(1,20): model = DecisionTreeClassifier(max_depth=num_layer) model = model.fit(X_train, Y_train) yp_train=model.predict(X_train) yp_test=model.predict(X_test)# print(y_pred.shape) test_results.append([num_layer,accuracy_score(Y_test, yp_test),recall_score(Y_test, yp_test,pos_label=0),recall_score(Y_test, yp_test,pos_label=1)]) train_results.append([num_layer,accuracy_score(Y_train, yp_train),recall_score(Y_train, yp_train,pos_label=0),recall_score(Y_train, yp_train,pos_label=1)])# Extracting datanum_layers = [result[0] for result in test_results]train_accuracy_values = [result[1] for result in train_results]test_accuracy_values = [result[1] for result in test_results]train_recall_0_values = [result[2] for result in train_results]test_recall_0_values = [result[2] for result in test_results]train_recall_1_values = [result[3] for result in train_results]test_recall_1_values = [result[3] for result in test_results]# Accuracyplt.figure(figsize=(10, 6))plt.plot(num_layers, train_accuracy_values, label='Train Accuracy', marker='o', color='blue')plt.plot(num_layers, test_accuracy_values, label='Test Accuracy', marker='o', color='red')plt.xlabel('Number of Layers in Decision Tree (max_depth)')plt.ylabel('Accuracy')plt.legend()plt.show()# Recall Y = 0plt.figure(figsize=(10, 6))plt.plot(num_layers, train_recall_0_values, label='Train Recall y=0', marker='o', color='blue')plt.plot(num_layers, test_recall_0_values, label='Test Recall y=0', marker='o', color='red')plt.xlabel('Number of Layers in Decision Tree (max_depth)')plt.ylabel('Recall Y = 0')plt.legend()plt.show()# Recall Y = 1plt.figure(figsize=(10, 6))plt.plot(num_layers, train_recall_1_values, label='Train Recall y=1', marker='o', color='blue')plt.plot(num_layers, test_recall_1_values, label='Test Recall y=1', marker='o', color='red')plt.xlabel('Number of Layers in Decision Tree (max_depth)')plt.ylabel('Recall Y = 1')plt.legend()plt.show()
Training Optimal Model
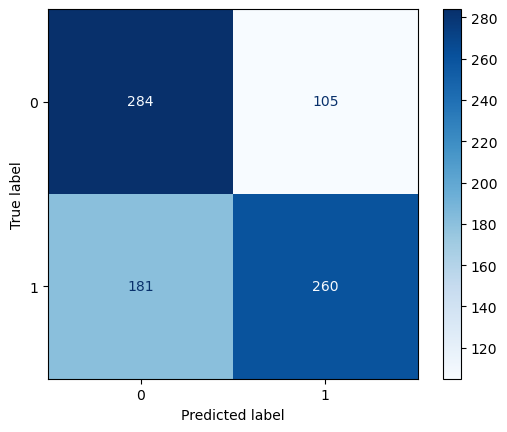
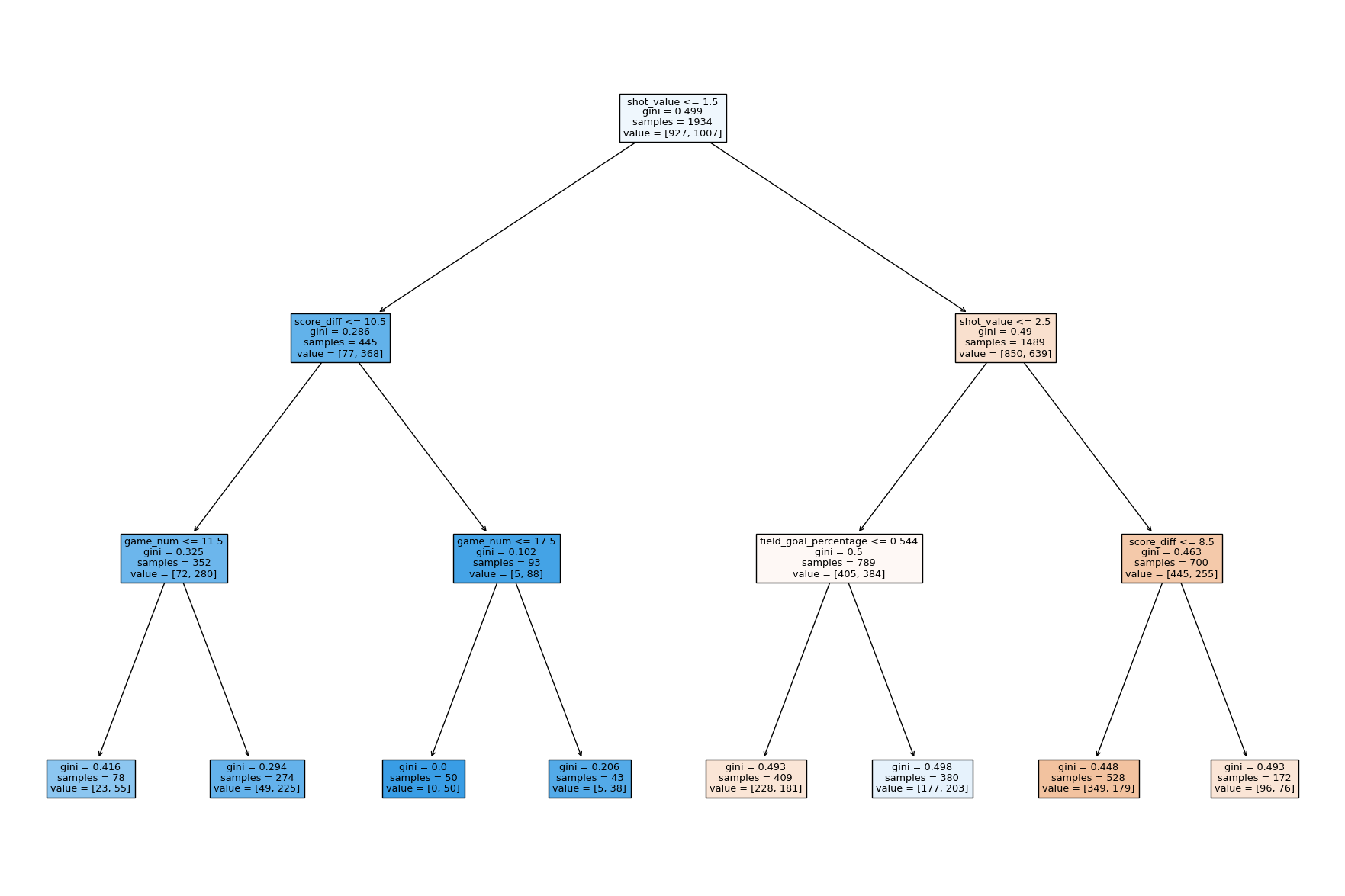
Based on the graphs, it appears that an optimal model would have three layers (a depth of 3). Consequently, we will re-train the decision tree using this optimal hyperparameter obtained from the plot above in the code below. Additionally, in the code chunk we will define and use a function that generates a confusion matrix plot, display metrics, and decision tree.
After tuning the hyperparameter, the model’s accuracy improved to 65.5%, marking a notable 13% enhancement compared to the baseline and a 9.5% improvement over the untuned version. Delving into the confusion matrix, it becomes evident that the model accurately predicted made shots (class 1) in 71.2% of cases, while achieving a 61.1% accuracy in identifying missed shots (class 0). This nuanced evaluation provides insights into the model’s strengths and areas for potential refinement. Notably, the absence of the ‘lag’ variable in the decision tree suggests its limited influence on the model, aligning with the initial hypothesis of its lower predictive power.
In summary, the hyperparameter-tuned decision tree exhibits improved accuracy and provides valuable insights into feature importance. The visualization underscores the significance of ‘shot_value’ and ‘field_goal_percentage’ in predicting shot outcomes, while the negligible role of the ‘lag’ variable aligns with expectations, emphasizing the model’s capacity to discern key predictors in the dataset.
Random Forest
Disclaimer: Although the preceding code and analysis successfully meet the assignment requirements, I also wanted to explore the application of random forests. This section will be more concise, but includes the necessary code and some analysis for random forests.
Theory
A random forest differs from a single decision tree in that it is an ensemble or a collection of decision trees. Instead of relying on the prediction of a single tree, a random forest aggregates the predictions of multiple trees to make a more robust and accurate prediction. Every tree in the ‘random forest’ is trained on a random subset of the data and features, introducing diversity in the models. During predictions, the random forest averages or takes a vote of the individual tree predictions, reducing the risk of overfitting and improving generalization performance. This ensemble approach makes random forests particularly effective in handling complex datasets and enhancing the stability and reliability of the overall model.
Implementation
The following code imports necessary libraries, splits the data into training and test sets, creates a Random Forest Classifier model, trains it on the training data, predicts outcomes on the test data, and then prints the accuracy of the model’s predictions.
Code
# load relevant librariesimport pandas as pdimport numpy as npfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.metrics import accuracy_score, confusion_matrix, precision_score, recall_score, ConfusionMatrixDisplayfrom sklearn.model_selection import RandomizedSearchCV, train_test_splitfrom scipy.stats import randint# Split the data into training and test setsX_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2)# Create the modelmodel = RandomForestClassifier()model.fit(X_train, Y_train)Y_pred = model.predict(X_test)accuracy = accuracy_score(Y_test, Y_pred)print("Accuracy:", accuracy)
Accuracy: 0.6365280289330922
/var/folders/lb/dk54cbx965z7nj61zps2fzr00000gn/T/ipykernel_50519/4200927063.py:14: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples,), for example using ravel().
model.fit(X_train, Y_train)
We can see that without any tuning, the random forest almost matches the accuracy of the hyperparameter-tuned decision tree. Let’s visualize the first three trees in the random forest below.
Code
# Export the first three decision trees from the forestfor i inrange(3): tree = model.estimators_[i]# Plot the tree plt.figure(figsize=(10, 8)) plot_tree(tree, filled=True, feature_names=X_train.columns, class_names=['0', '1'], rounded=True, proportion=True) plt.title(f'Decision Tree {i +1}') plt.show()
Hyper-Parameter Tuning
Next, we will utilize a random search with cross-validation to find the best hyperparameters within a specified range. The best model is then stored, and the optimal hyperparameters are printed.
Code
param_dist = {'n_estimators': randint(50,500),'max_depth': randint(1,20)}# Convert Y_train to a one-dimensional arrayY_train = Y_train.values.ravel()# Create a random forest classifiermodel = RandomForestClassifier()# Use random search to find the best hyperparametersrand_search = RandomizedSearchCV(model, param_distributions=param_dist, n_iter=5, cv=5)# Fit the random search object to the datarand_search.fit(X_train, Y_train)# Create a variable for the best modelbest_rf = rand_search.best_estimator_# Print the best hyperparametersprint('Best hyperparameters:', rand_search.best_params_)
Best hyperparameters: {'max_depth': 4, 'n_estimators': 417}
Training Optimal Model
Using the above hyperparameters, let’s train the optimal random forest model.
Code
# Predictions on the test setyp_test = best_rf.predict(X_test)
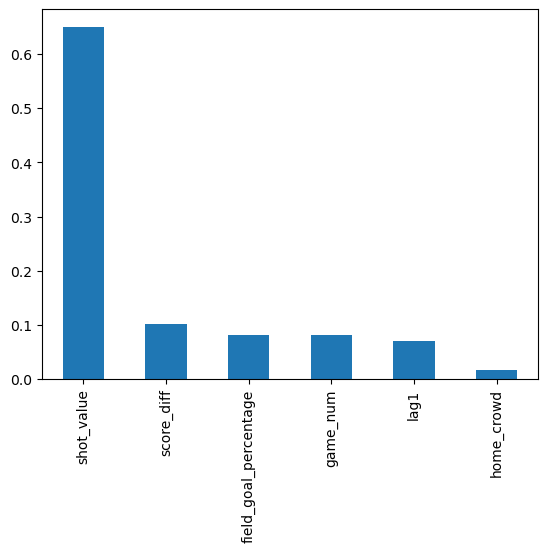
# Create a series containing feature importances from the model and feature names from the training datafeature_importances = pd.Series(best_rf.feature_importances_, index=X_train.columns).sort_values(ascending=False)# bar chartfeature_importances.plot.bar()
Conclusion
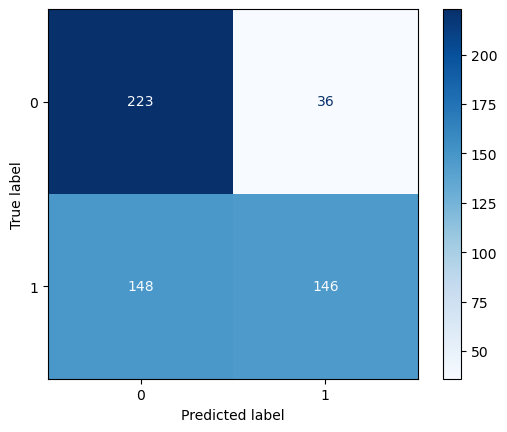
The tuned Random Forest model exhibits improved accuracy compared to the tuned Decision Tree, achieving an accuracy of 66.7%. Notably, the Random Forest model demonstrates higher positive recall (Y=1) and precision, indicating enhanced performance in correctly identifying instances of made shots.
The above code calculates the feature importance from the tuned Random Forest model and creates a bar chart to visualize the importance of each feature in predicting shot outcomes. The resulting chart helps identify which features have the most significant impact on the model’s decision-making process. The bar chart reveals, expectedly, that shot value has the most significant impact by a large margin. At the same time, lag1 exhibits a meager impact, aligning with similar results from the tuned decision tree.